最近更新2026年3月25日
OpenCalw镜像版本说明
镜像为,原生OpenClaw镜像镜像目前发布了以下版本
OpenClaw 接微信
将手机微信更新到最新版,就可以在设置中找到这个ClawBot,就可以手机上使用OpenClaw了
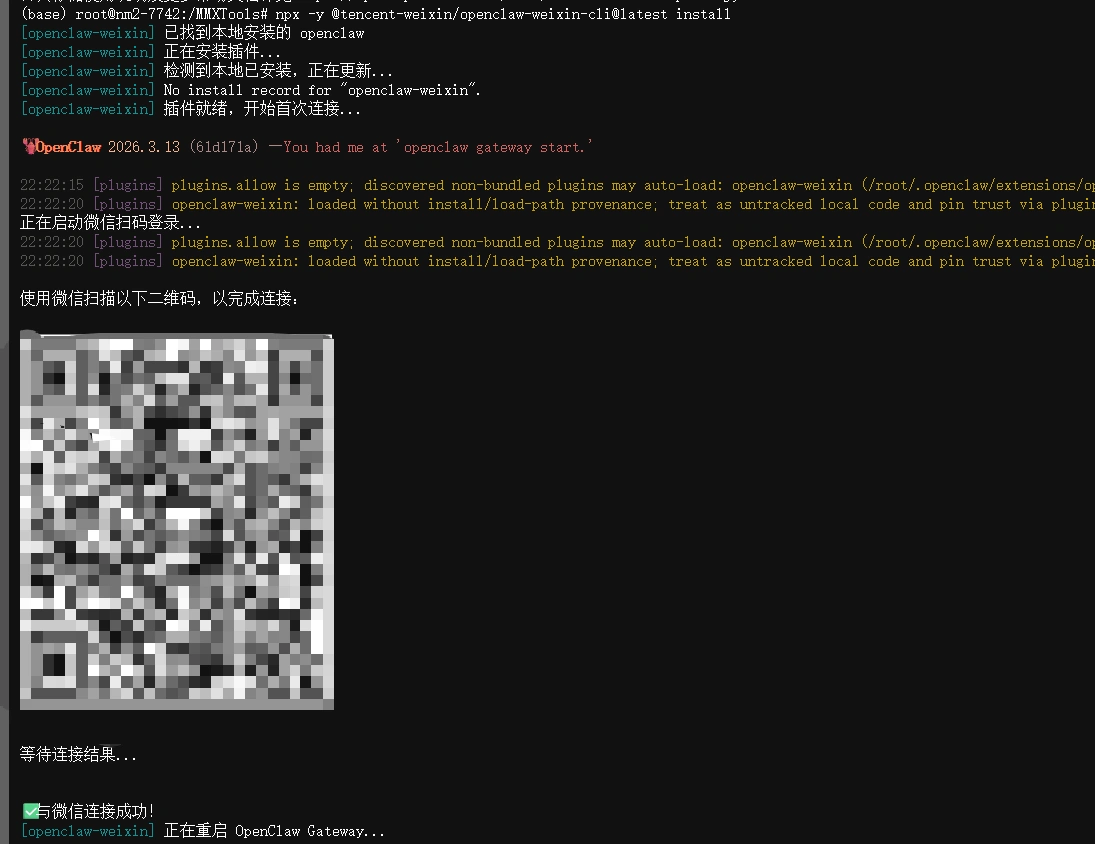
打开云端的OpenClaw终端,运行
npx -y @tencent-weixin/openclaw-weixin-cli@latest install
出现二维码,手机微信扫一下就可以连接。
此时需要运行
sudo systemctl restart openclaw
手机上就可以以直接和openclaw对话了。
,,,,,,,
当然,你需要先把下面的部署好,,,
养虾交流群 - 微信
开通了一个OpenClaw的交流群,需要进群的可以通过助理拉进群
有问题群里可以聊聊
云镜像部署-Ubuntu
我们使用的是保守策略,在云端虚拟环境进行部署研究、验证、学习,
大家可以放心使用电脑、手机浏览器体验小龙虾,本镜像不会对本地造成任何,浏览器只是一个控制台,文件编辑删除操作什么的只在云端机器上发生。
验证成功以后,可以再在本地部署它。
创建时,可以使用 4090、3090,24GB的显存,可以直接跑
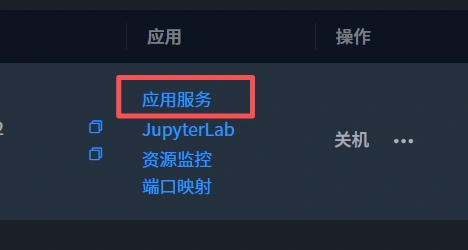
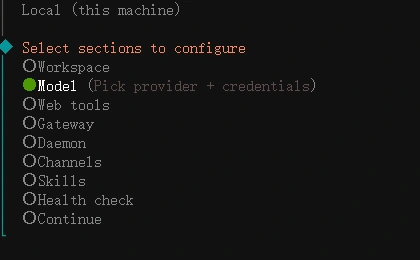
打开选”应用服务“,稍等加载完成,可以看到下面的界面
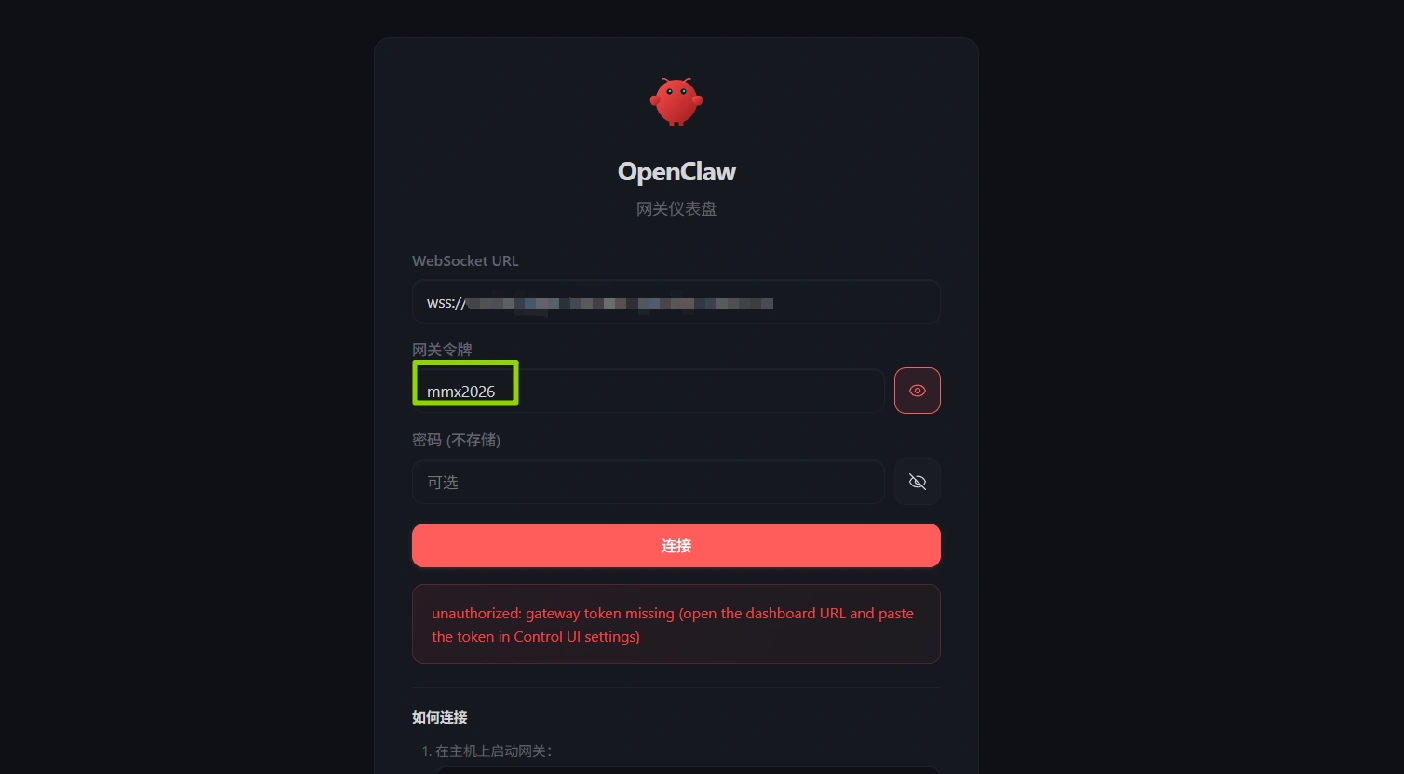
先把令牌“mmx2026”写上,然后点“连接”,一直点“连接”,多点几次,不要管爆红,直到出现下面的页面
默认调用的是”ollama/qwen3.5:9b“模型(9b模型,1张4090、3090可跑),调用本地ollama模型,无需api,可以直接使用,第一次使用需要加载模型,会慢一些
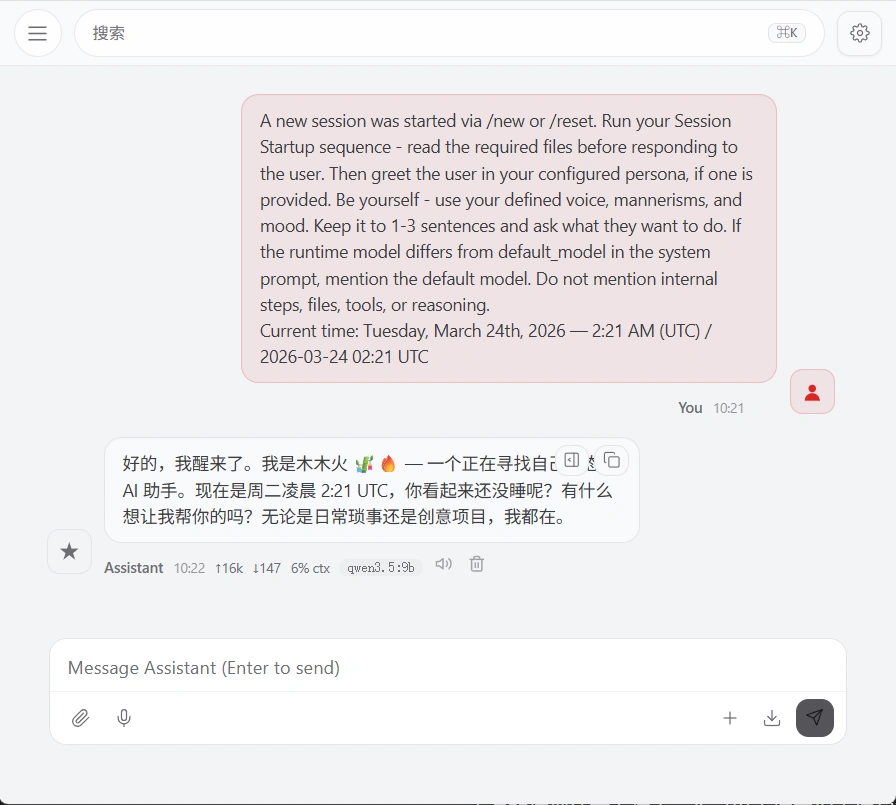
预设了ai助理“木木火”,通过 /new 唤醒,没有更多的设置,可以自己进行配置。
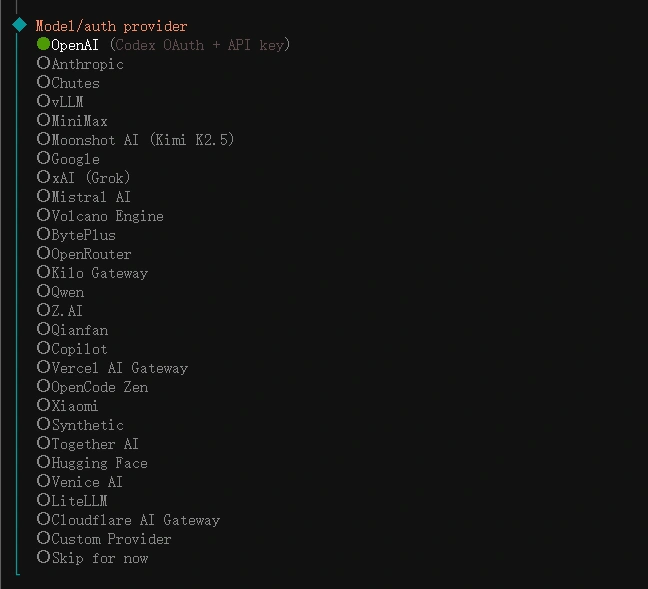
如果你需要更聪明的大脑,那你可以自己设置外部API,,
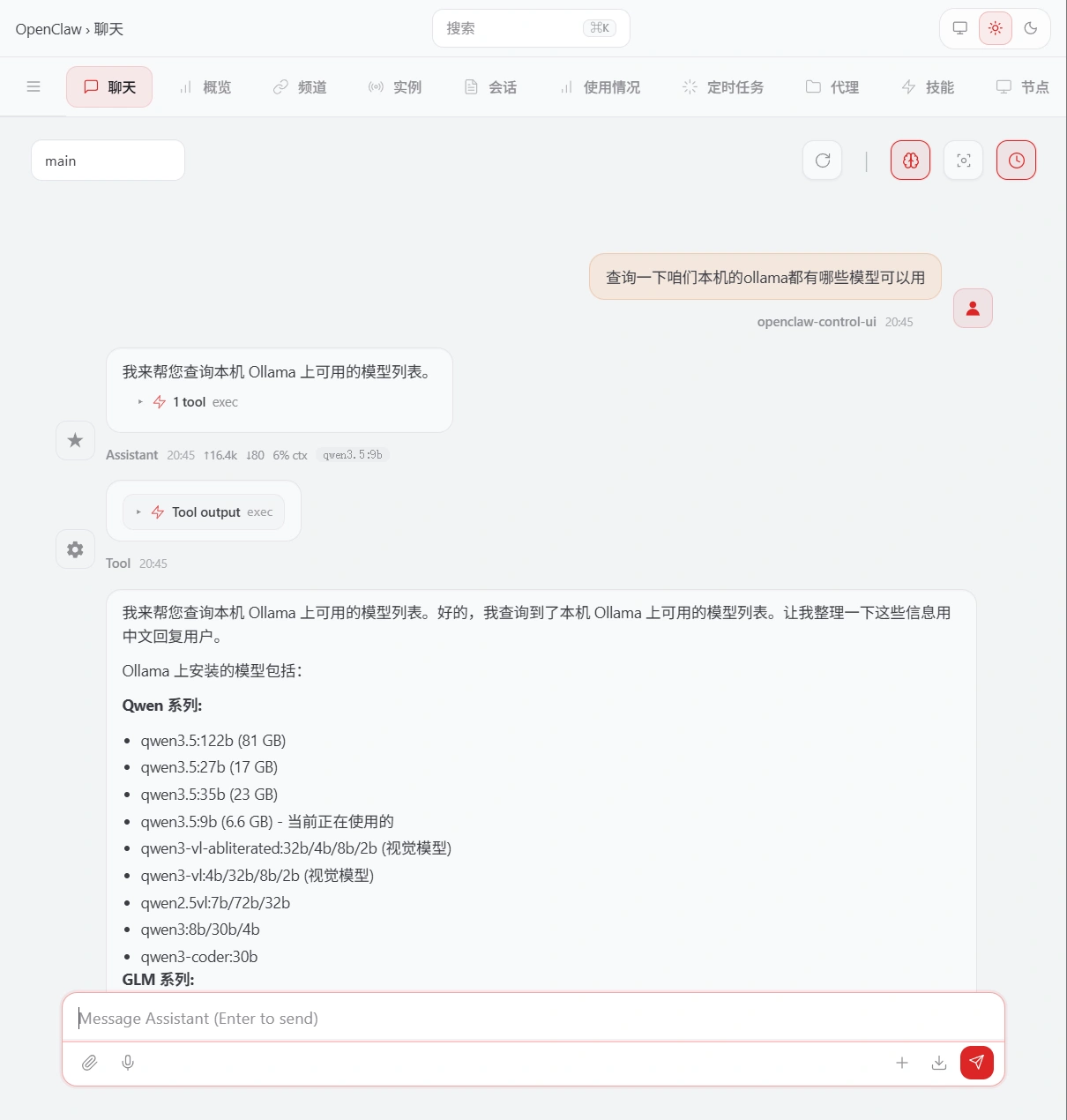
更多的模型还在上传中,你可以直接实例内询问更新到哪些模型了,
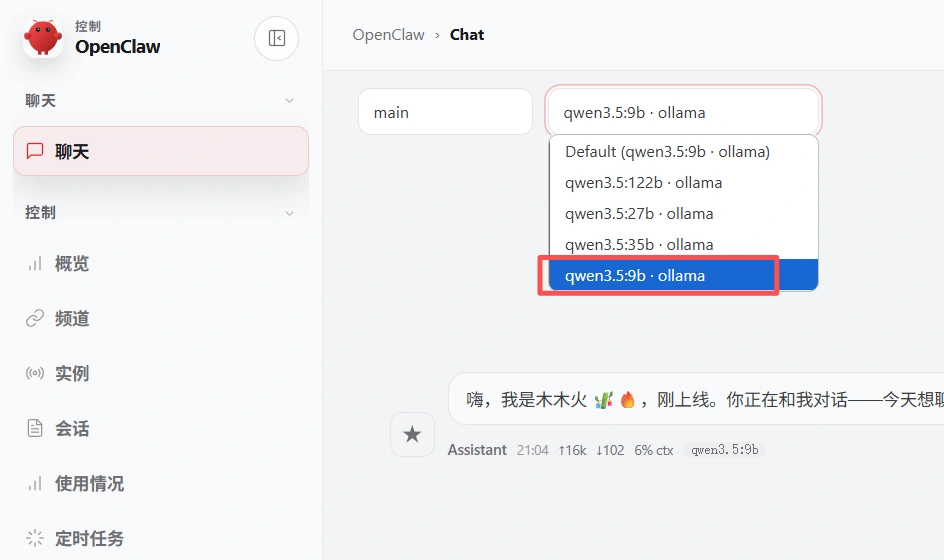
你还可以直接让它切换到已有的ollama模型
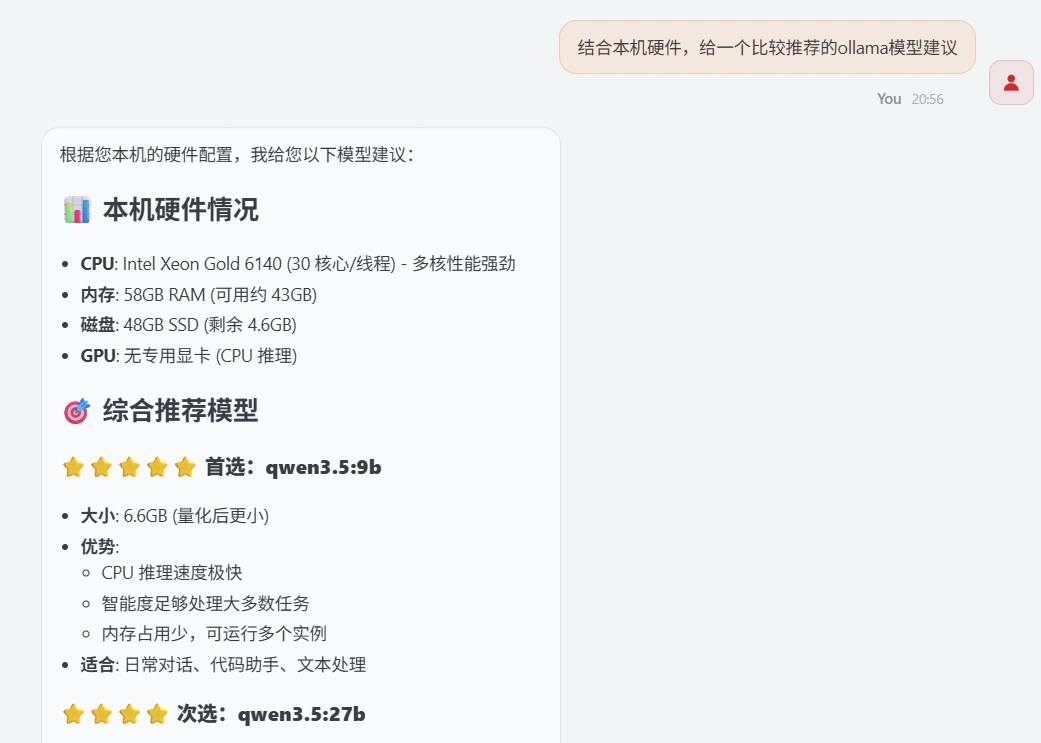
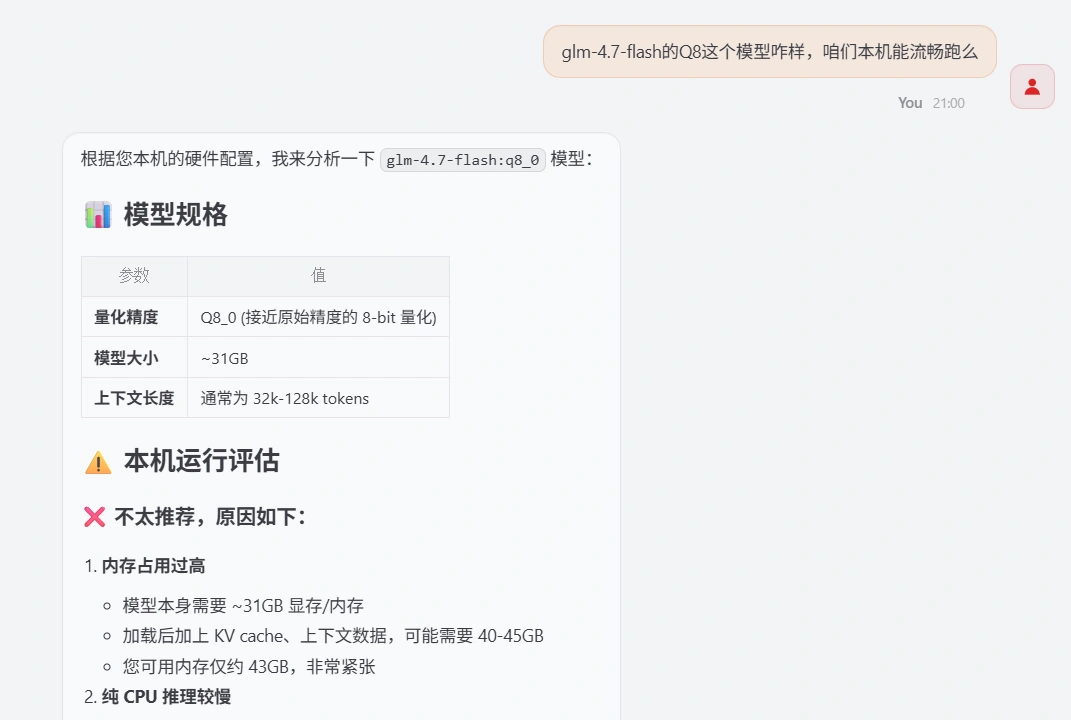
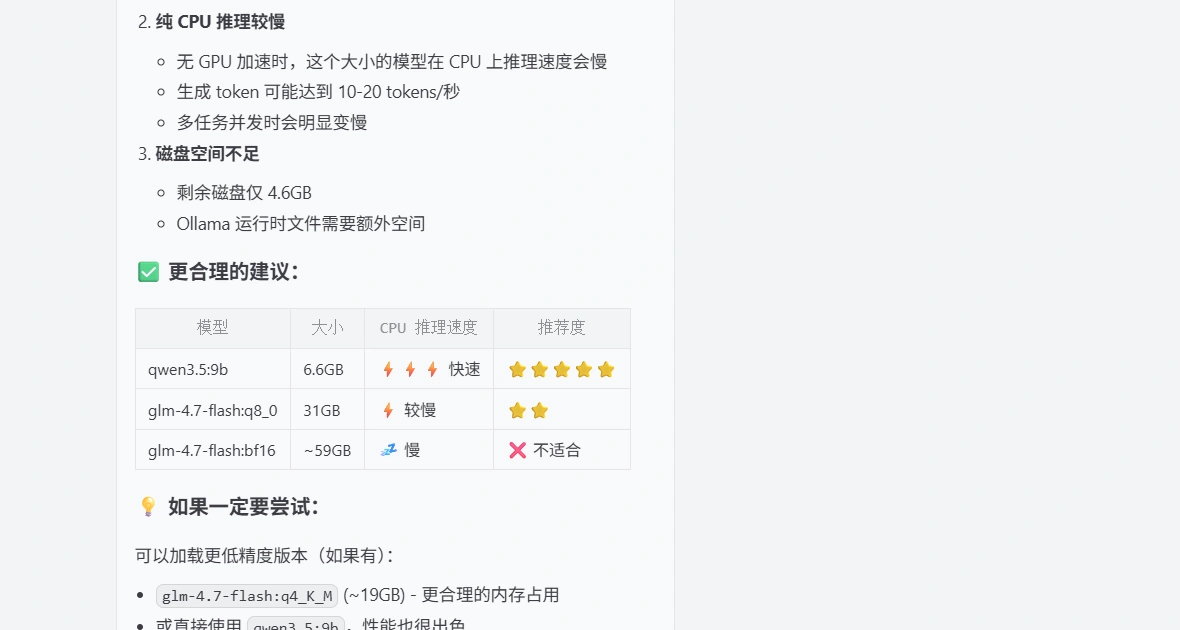
你也可以让它根据本机硬件进行推荐
再打听下能不能跑glm的模型
还可以直接让它给切换指定的模型
也可以
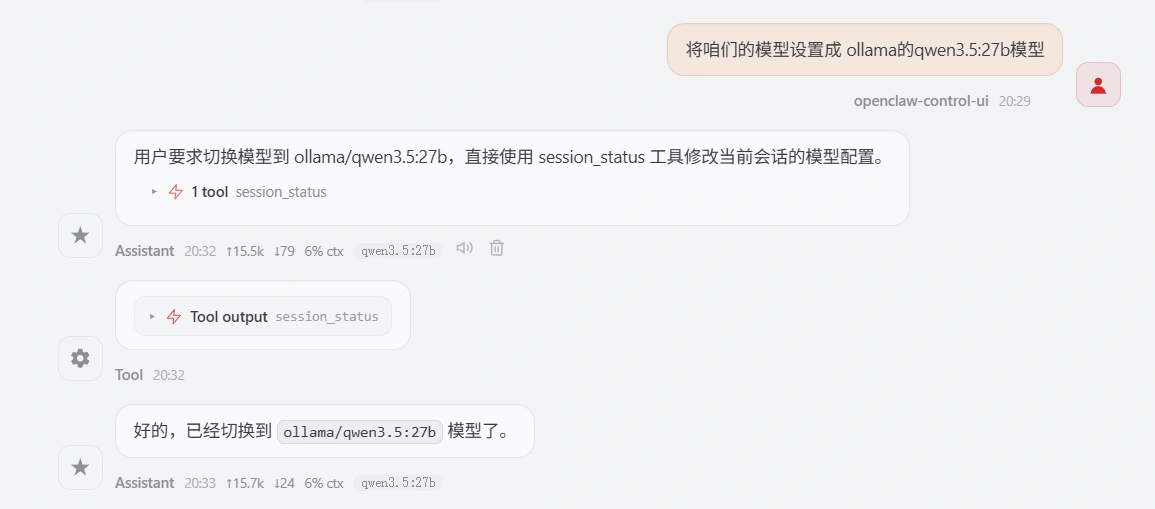
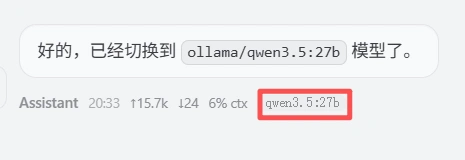
24GB的显存勉强能跑 qwen3.5:27b 的模型,你可以使用 将咱们的模型设置成 ollama的qwen3.5:27b模型 切换,这个在单卡环境下切换会很慢很慢
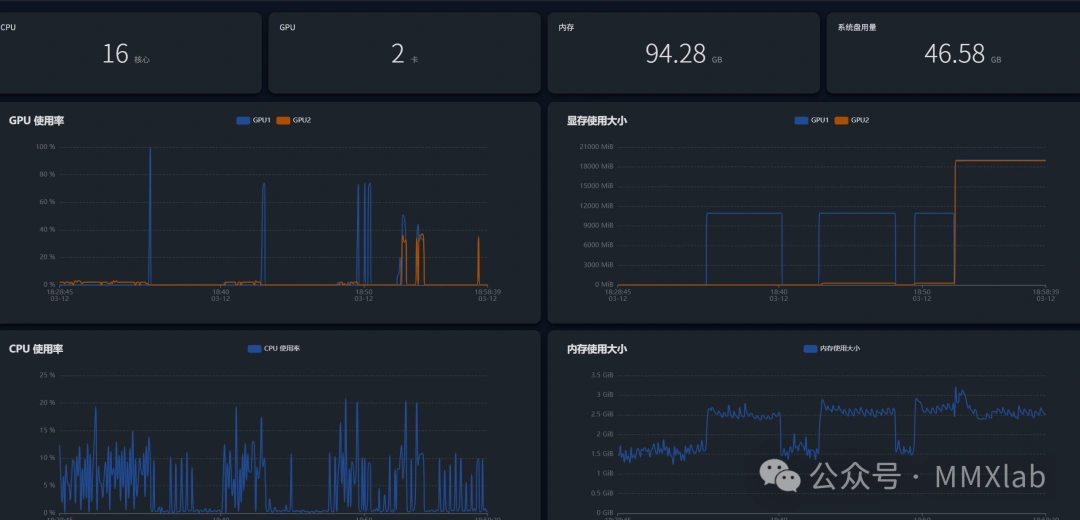
右下角显示 qwen3.5:27b 表示切换成功,使用双卡可跑
ollama支持多卡并行,你可以选择合适的显卡和模型来跑,具体的你可以直接在会话中提问本机适合什么模型
配置api模型,可以在jupyterlab中使用以下命令进行配置
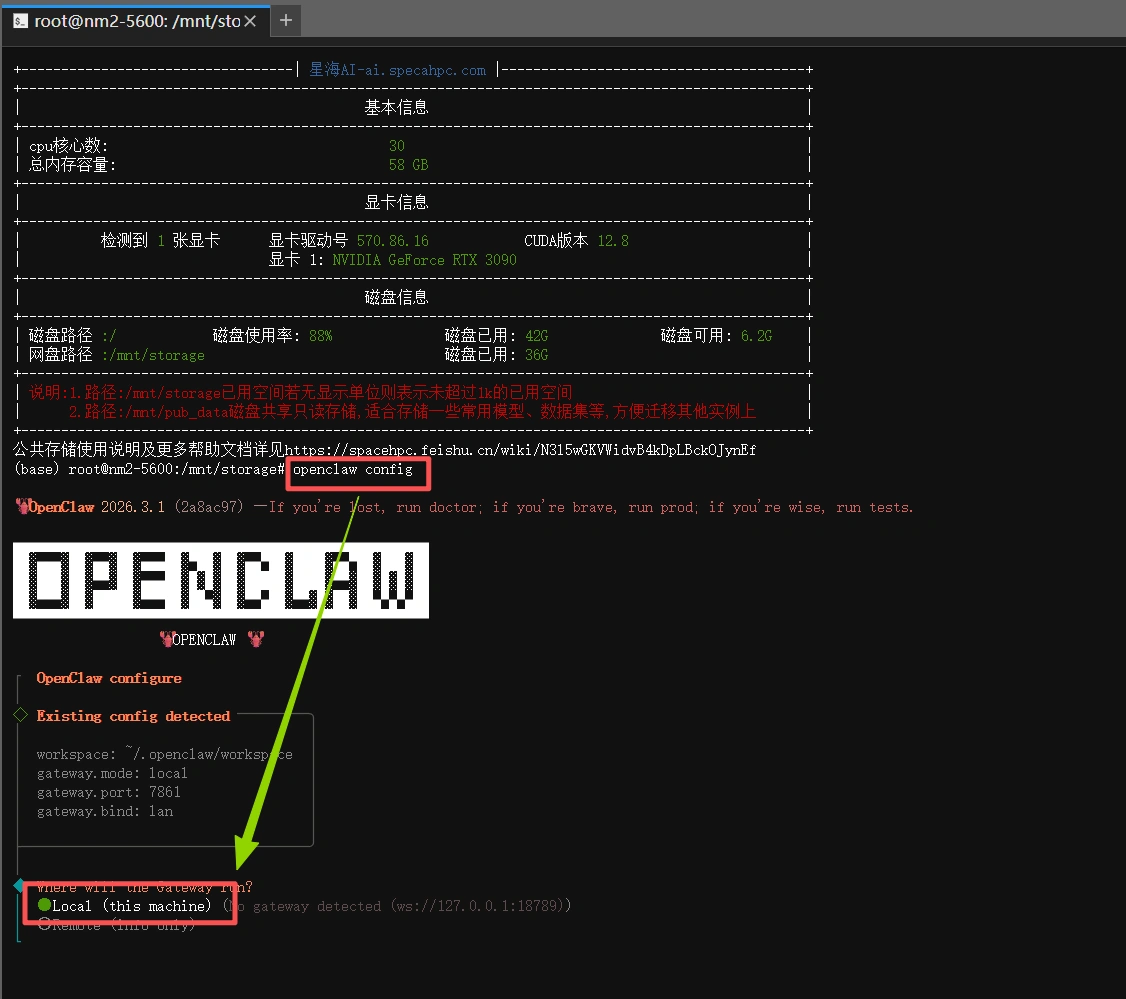
openclaw config
进入命令行
输入”openclaw config“
选择local
选择model
选择你的api平台
其他的,后续再完善吧,,,
云镜像部署-win
选择4090、3090的24GB显卡,
登录远程桌面
win系统,键盘按下 win + R ,
输入 mstsc ,确认
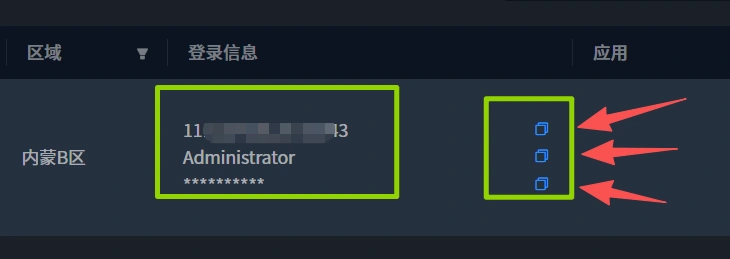
将信息依次填入,右侧小方块可以 一键复制
进入桌面后的操作
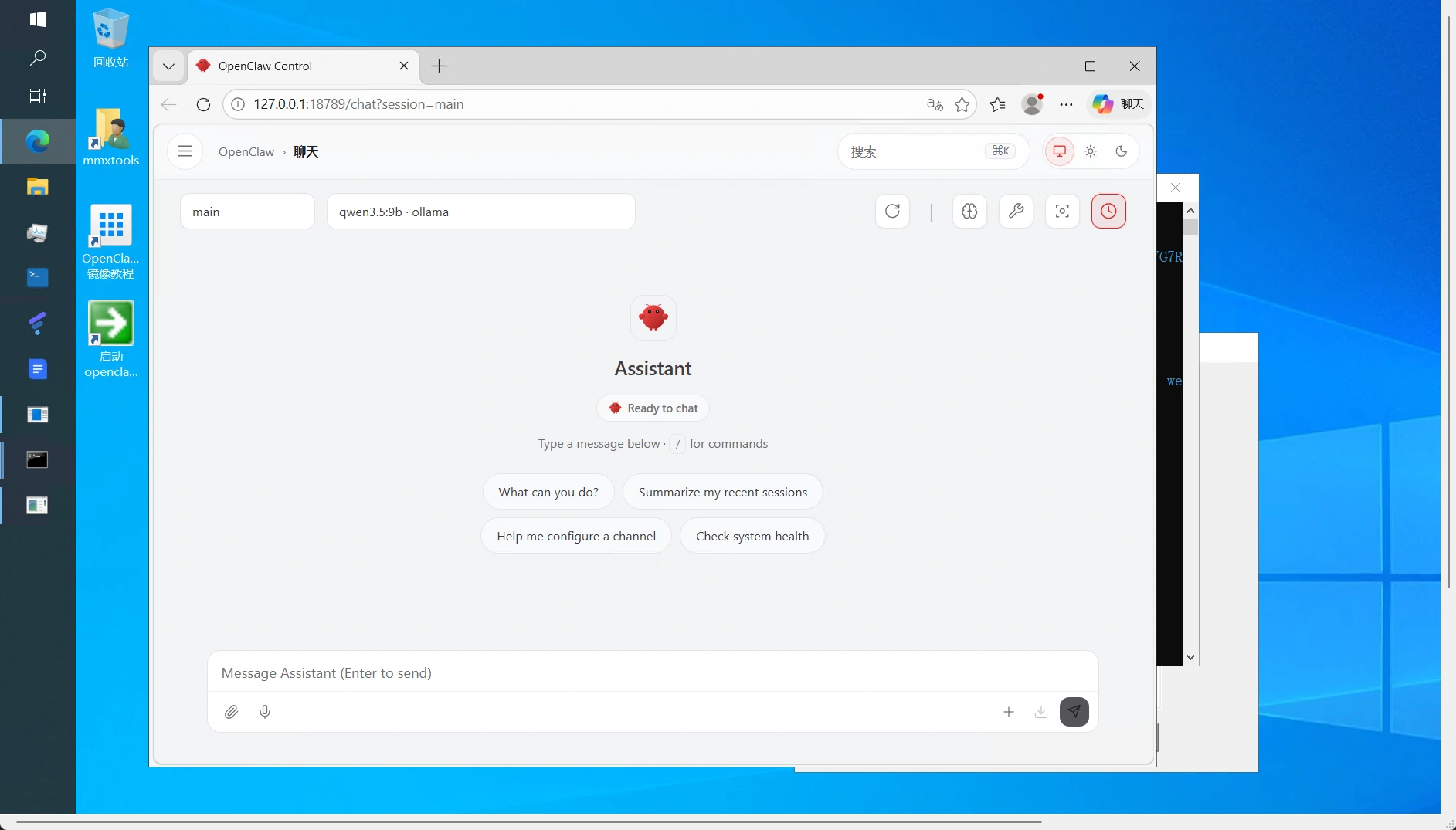
创建实例后,opencalw服务是自动启动的,无需操作,等着就行
程序会同时打开很多命令框,你不要管,不要关,,,
你等待启动就可以了,如下图
如果你把所有命令窗口都关了,你可以手动的使用下方方式启动openclaw
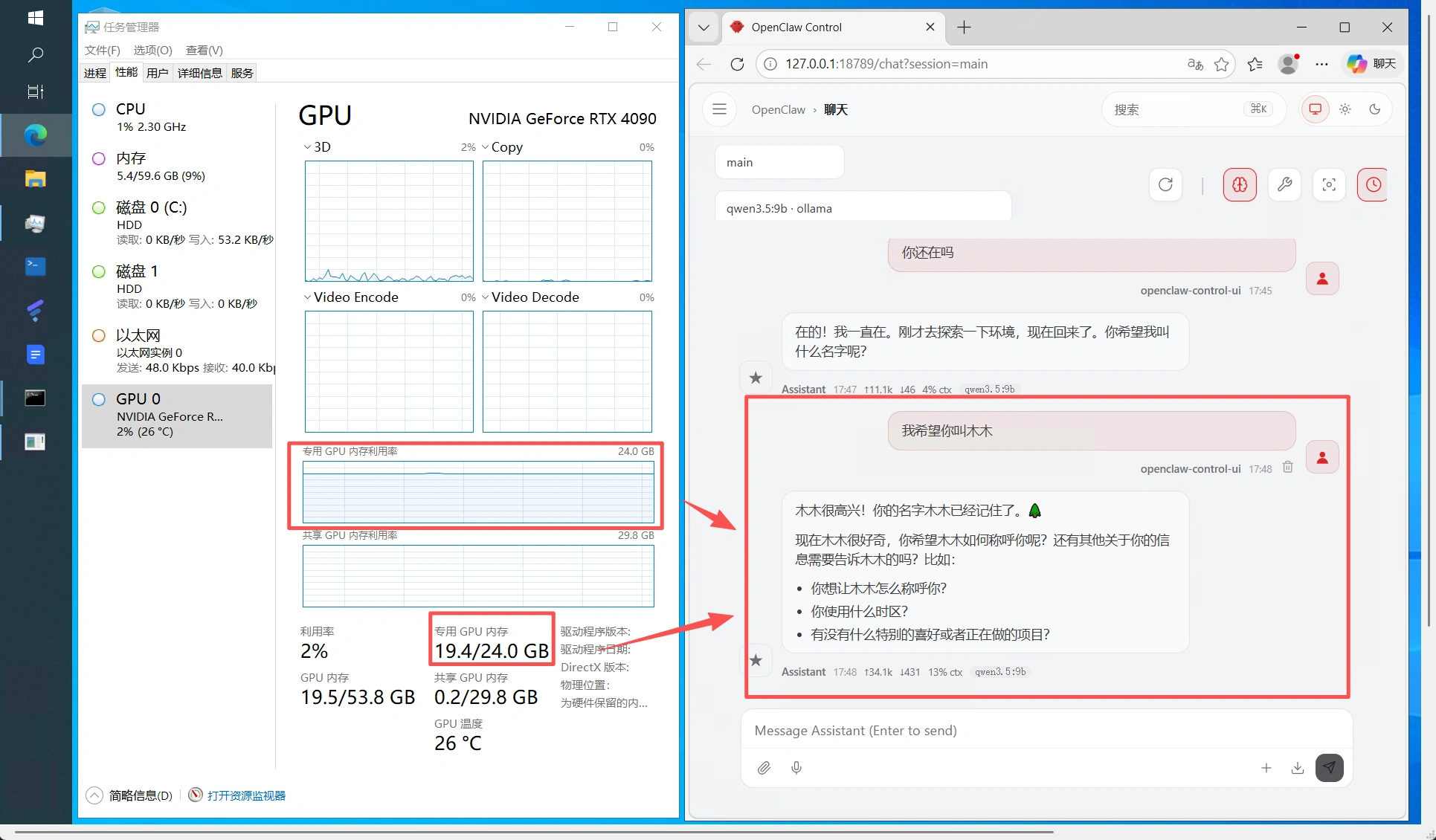
如果你不知道是否成功,可以打开任务管理器
看到显存有占用,就知道启动是否正常了,,
其他问题,群里交流吧


 简体中文
简体中文
 English(英语)
English(英语)
 日本語(日语)
日本語(日语)
 Deutsch(德语)
Deutsch(德语)
 Русский язык(俄语)
Русский язык(俄语)
 بالعربية(阿拉伯语)
بالعربية(阿拉伯语)
 Türkçe(土耳其语)
Türkçe(土耳其语)
 Português(葡萄牙语)
Português(葡萄牙语)
 ภาษาไทย(泰国语)
ภาษาไทย(泰国语)
 한어(朝鲜语/韩语)
한어(朝鲜语/韩语)
 Français(法语)
Français(法语)

 雷达卡
雷达卡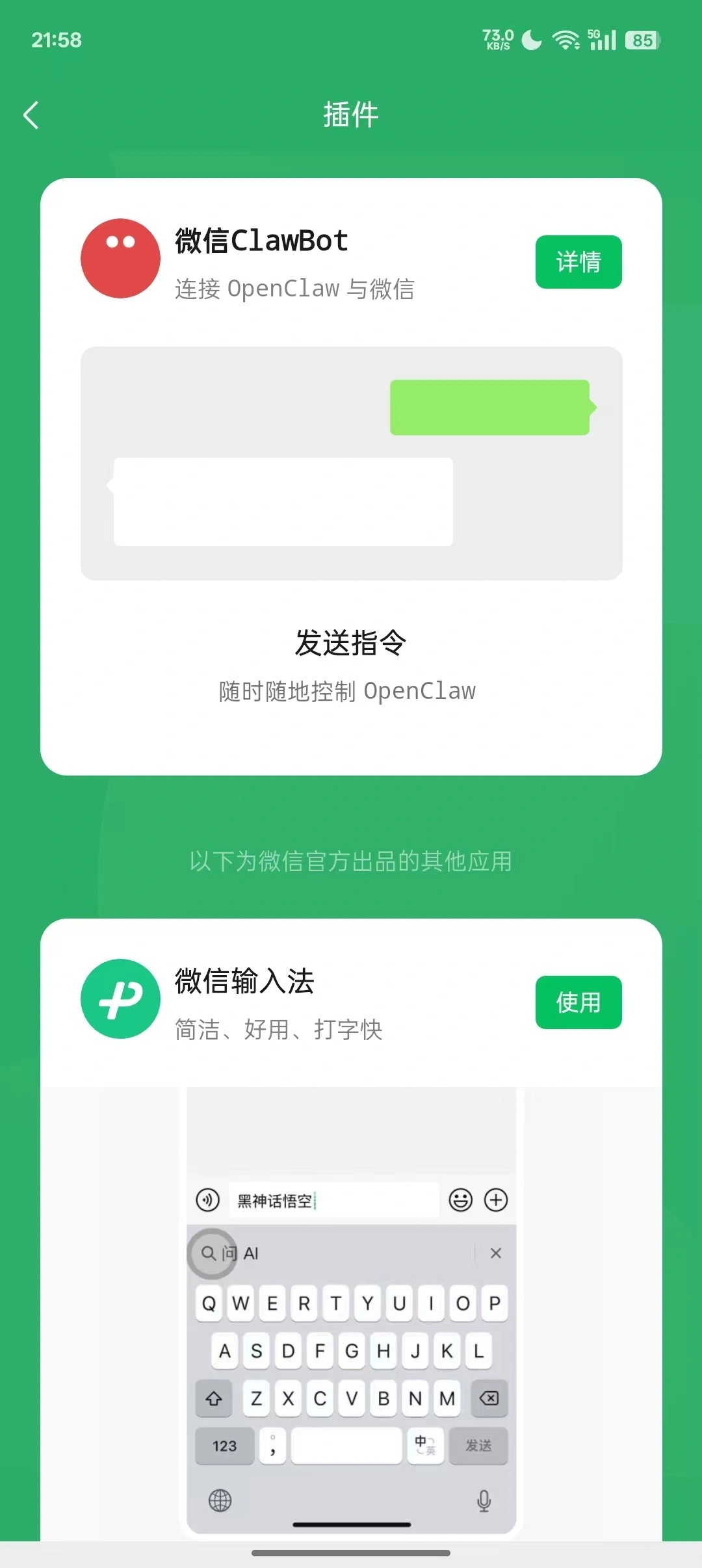




 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 照妖镜
照妖镜