|
Soul APP旗下AI Lab重磅发布FlashTalk!这是一款超低延迟的实时数字人驱动框架。仅需一张图+一段音频,即可在RTX 4090上实现130 FPS的惊人推理速度。完美解决ID漂移与口型不同步问题,支持写实/动漫双风格,实时交互数字人迎来了新霸主! 一、SoulX-FlashTalk最新数字人技术介绍兄弟们,Soul APP 这次不只做社交,开始搞黑科技了! 提到 Soul,大家想到的可能是“灵魂社交”、“捏脸”。 但最近,Soul 旗下的 Soul AI Lab 默默憋了个大招,发布了一款针对实时交互数字人的框架——SoulX-FlashTalk。 为什么我要特意介绍它? 因为目前的数字人模型(比如 SadTalker、InfiniteTalk ),虽然效果不错,但太慢了!想做直播或者实时对话,延迟感很重。 而 FlashTalk 的出现,就是为了“唯快不破”。 官方数据:在 RTX 4090 上,推理速度高达 130 FPS! 这哪里是实时,简直是超实时! 什么是 FlashTalk?
简单说,它是一个“音频驱动的说话人生成框架”(Talking Head Generation)。 - 输入:一张人脸照片(源图像) + 一段音频。
- 输出:一段这个人脸说话的视频,口型完美匹配,表情自然。
SoulX-FlashTalk 是一个针对高保真流媒体优化的 14B 参数系统。通过采用双向流蒸馏(Bidirectional Streaming Distillation) ,我们保留了块内双向注意力机制,从而维护了时空相关性。这种设计显著简化了训练过程。该模型仅需 1000 步 SFT 和 200 步蒸馏即可收敛, 效率提升高达 23 倍 。为了确保无限稳定性,我们引入了多步回顾性自校正机制(Multi-step Retrospective Self-Correction Mechanism) 。结合我们全栈加速套件,SoulX-FlashTalk 成为首个实现 0.87 秒启动延迟和 32 FPS 实时吞吐量的 14B 级系统。 它主打的核心场景就是“高保真”与“实时性”。 不仅要画质好,更要速度快,非常适合用在AI 客服、虚拟主播、游戏 NPC 等需要即时反馈的场景。 官方的一些案例,SoulX-FlashTalk 支持实时推理,延迟极低。(目前ComfyUI上还不支持实时) 是不是看着还不错。接下来我们一起来测评看看实际效果。 超好玩,推荐给你! 二、相关安装目前ComfyUI已经有插件支持了, 不过目前好像就只能图片+音频做数字人视频,实时的暂时还未支持。 插件地址:https://github.com/HM-RunningHub/ComfyUI_RH_FlashTalk 模型主要安装两个 最近分别放到: - ComfyUI/models/Soul-AILab/SoulX-FlashTalk-14B/
- ComfyUI/models/wav2vec/chinese-wav2vec2-base/
我网盘也提供了,大家自取 三、测评体验
不再低调!发布 FlashTalk:一张图+一段话,快速生成唇形同步数字人视频
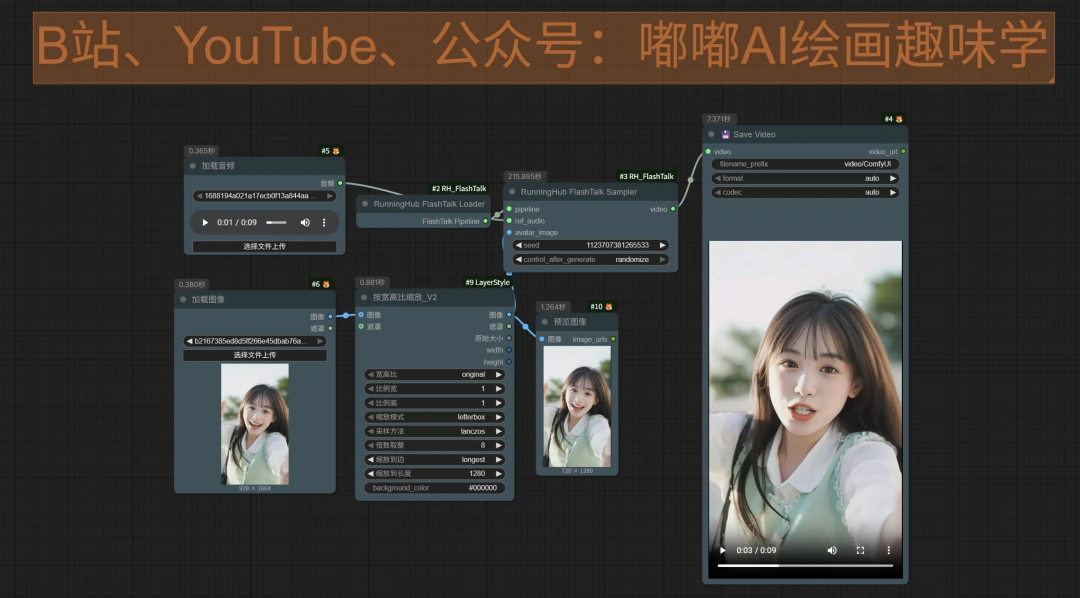
节点很简单,传入音频和图像,就可以直接生成了。 目前我测试下来发现2个问题: - 不能设定分辨率,不管传入多少,传出来的都是固定的448x768
- 横屏的传入最终出来的也是上面这样的竖屏
效果的话还不错,速度还挺快。 29秒的时长跑了12分钟就出来了。 9秒的时长跑了3分50秒。 目前暂时不能跑实时的,还是传统的图片+音频来生成 按官方说的,目前显存占用24G,所以大家现在RH上跑,模型我这会还在上传到网盘,到时候大家自己测试看看。 案例展示
看几个我实际跑的案例,这里没有涉及到提示词,只要音频+图片就行。 整体测试下来,我感觉还不错的,唇形同步的还算到位,但是这个分辨率和比例问题限制的太死了,不知道后续能不能开放。 但总得来说,还算不错的一个新的技术,而且这个厉害的是后期的实时,期待官方快点开放相关模型。
| 

 简体中文
简体中文
 English(英语)
English(英语)
 日本語(日语)
日本語(日语)
 Deutsch(德语)
Deutsch(德语)
 Русский язык(俄语)
Русский язык(俄语)
 بالعربية(阿拉伯语)
بالعربية(阿拉伯语)
 Türkçe(土耳其语)
Türkçe(土耳其语)
 Português(葡萄牙语)
Português(葡萄牙语)
 ภาษาไทย(泰国语)
ภาษาไทย(泰国语)
 한어(朝鲜语/韩语)
한어(朝鲜语/韩语)
 Français(法语)
Français(法语)


 雷达卡
雷达卡

 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 照妖镜
照妖镜